
By Steven Liang, Manager of Generative AI Application, Synology
Synology is a data management solutions provider. With a global user base of 13 million installations, we handle approximately 280,000 technical support tickets annually, from simple product inquiries to complex configuration consultancy in enterprise IT environments. To create a high-quality and rapid customer service experience, we at Synology established an AI team four years ago and utilized machine learning techniques to recommend relevant reference materials to users when they ask questions. This approach enables about 50,000 of our annual technical support cases to be resolved quickly.
Then there came the rise of large language models (LLMs) such as GPT-3 in 2020 and ChatGPT at the end of 2022, which revolutionized the field of natural language processing. These models demonstrated unprecedented capabilities in understanding and generating human-like text, opening new possibilities for enhancing customer support systems.
LLMs Aren’t the Answer for Better Customer Service, At Least Not Directly
While large language models have gained significant popularity, they aren’t directly suitable for addressing our support issues. There are several reasons for this. First, LLMs’ training data includes a mix of sources, such as third-party forums, outdated articles, and user-generated content, which may not always reflect the most current or accurate information.
Moreover, these models may also struggle to offer precise technical knowledge or solutions for unique support cases that require context-specific understanding. When a user presents a problem, we need to decide whether to answer based on the information provided, ask for more details, or determine which questions are appropriate to ask. This requires not only the broader context of the problem, but also a nuanced understanding of Synology’s support practices and limitations.
This is where Retrieval-Augmented Generation (RAG) comes in as an excellent solution. RAG is a technique widely used to optimize the output accuracy of an LLM. It retrieves data from external authoritative databases to provide accurate contextual information, which the AI then uses to generate suitable responses. This approach helps the result maintain accurate, relevant, and ensure responses comply with internal policies.
Prioritizing data privacy as the foundation
Our RAG-based support system is built on a four-step architecture designed to ensure customer privacy, accuracy, and efficiency. The process begins with building a RAG database, where we utilize historical technical service data from one year ago to the present day. This crucial step includes a thorough de-identification process to protect our customers’ privacy.
After de-identification, we perform chunking and indexing on the data for more efficient processing when building our RAG database. Additionally, we apply semantic embedding to these chunks, enabling advanced semantic similarity searches by identifying and retrieving contextually relevant content. From our experience, it’s best to retain more contextual data when performing chunking, allowing some overlap between each data segment. This approach leads to search results that better align with the customer’s intent.

Teaching AI to “understand” customer needs
The next phase involves processing new support tickets. When a customer submits a ticket, we first perform de-identification to anonymize sensitive information and protect their privacy. A Synology rep will then analyze the ticket to understand the customer’s intention and determine whether an AI response is needed. For example, suppose the customer’s support ticket involves requesting a technical support consultant, such as when a customer actively requests remote connection diagnosis or troubleshooting. In that case, there’s no need for AI to provide an answer.
The key to the intent analysis stage lies in the response criteria, as it is crucial to define the system’s response strategies for different customer intents and determine when the system should either transfer to a service specialist, ask the customer for more information, or directly extract and generate content from the database.
Retrieve relevant information from the RAG database
Once AI understands the context more thoroughly, the third step involves establishing a robust search mechanism. The customer’s question is rewritten to optimize it for extracting information from our RAG database. We also utilize semantic search method that allows us to extract past tickets of relevant types and provide a rich context for generating responses.
The quality of our search results is heavily dependent on our data segmentation approach. To address this, we’re developing an advanced Re-ranking model that uses deep learning to re-calibrate search results based on calculated similarity scores. This additional processing layer aims to further enhance the relevance and accuracy of the information we provide, ultimately improving our ability to meet our customers’ needs more precisely.
Generating policy-compliant responses with human oversight
In the final step, we generate answers based on the processed information. We create a prompt using the analyzed intention, the rewritten question, and the extracted relevant data. The generated response then undergoes a series of policy checks and more guardrails to ensure we don’t provide sensitive information like console commands, remote access details, or anything that’s contextually accurate but may not be available or applicable in certain scenarios. These checks help maintain security and keep responses within the appropriate scope of AI-assisted support.
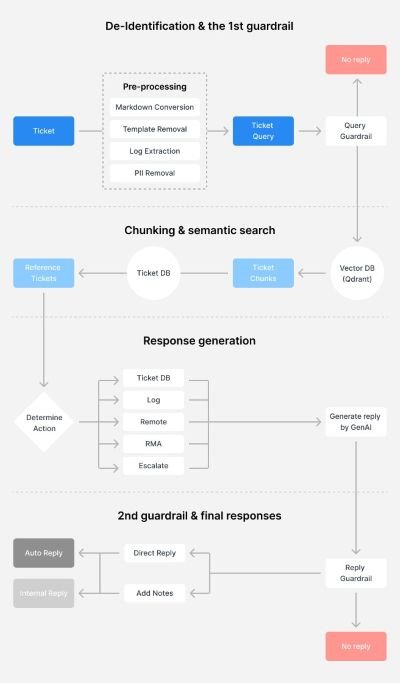
Finally, the guardrail would help determine whether the generated responses are valid for automated reply. Should the guardrail determine the tickets require support staff intervention, we then present the AI-generated suggestion to our customer support staff. These support staff makes the final judgment on the appropriateness and accuracy of the response before it reaches the customer.
20x faster response, greater efficiency
The architecture allows us to incorporate generative AI while maintaining the high standards of accuracy and security that our customers expect from Synology support. By harnessing the power of LLM and RAG while automating responses to routine inquiries, we’ve achieved response times up to 20 times faster than before.
As we continue to refine our AI-powered support system, we’re focusing on enhancing response accuracy and relevance for our diverse global user base. We will continue to adapt to regional differences in product preferences, joint issues, and compliance policies. This approach ensures our AI-generated suggestions are technically accurate and aligned with local regulations and practices.
By providing more accurate responses, we aim to free up more of our support team to handle the trickier and more urgent issues that require a human touch. This helps us work more efficiently while still giving Synology customers the high-quality, personalized help they’ve come to expect from our customer support team.